
Writing a Tree-sitter grammar, I found the UX is great!
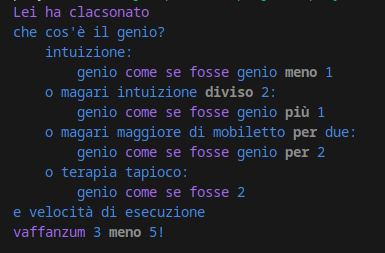
Syntax highlighting with my Tree-sitter grammar
In the last months I worked on a new project, a dashboard/blog/dataviz experiment focused on the city of Milan, and doing so started focusing on ways to automate and validate the integration of WebAssembly, DuckDB SQL, JS, Markdown and other things.
A concept I come across again and again playing with this is parsing. I use tools to parse Markdown, transpile Typescript into something the browser understands, translate schemas from JSON to Parquet to Vega-lite charts and a lot of other transformations.
I also have the pet peeve of validating as much as possible as early as possible, finding out, for example, if I’m trying to display a value that does not exist in a chart generated from a Parquet file in turn produced by a DuckDB query. Or maybe automate some step, like detecting which values could be displayed and how. These kinds of automations are hard.
Anyway, doing so I often come to a point where I think it would be great to be able to parse and manipulate code programmatically. Finding out types and function, allowing the user to input configuration as scripts that can be executed, reporting on errors, adding macros to languages that don’t have them (yet)).
But above all, I think it would be fun to perform these kinds of manipulations (even when they are likely a bad idea) and, who knows, one day even create yet another programming language. You know, the world needs another one!
So, I started looking into grammars, parsers and parser generators. It’s a concept I studied in the language and compilers course at university many years ago and I even wrote my own top-down parser to annotate natural language, but what about a full-fledged grammar?
What is a grammar anyway?
A generative grammar is a way to describe a formal language. “Formal” here means that the rules of the language are explicit, as opposed to “natural” languages like Spanish, and is generally possible to demonstrate whether a string is valid or not according to the rules. As a byproduct we can also get an idea of the structure of a string, assigning labels and finding hierarchies in its content (for example in a programming language we can have a function containing loops containing statements).
Writing a program that can actually do it, however is a complete different matter, and a fascinating topic I recommend if you are interested in theoretical computer science. From now on I’ll focus on the subset of grammars that are used in practice in software development.
Let’s imagine we have the symbols ), (, +, and 8. We can see how some
strings are valid:
88 + 88 + (8 + (8 + 8)) + 8
and others are not:
8 + + 88 +8 + ( 8
a generative grammar is based on a set of generation rules, each rule defines
how we can replace a symbol with a sequence of other symbols or terminals
(that is, symbols of th alphabet like the + here, so called because they are
not replaced by anything). Given a special starting symbol S you can apply
rules in any order, replacing symbols with other symbols with other symbols
until you have a sequence of only terminals. Every terminal string obtained this
way is valid.
In this case, we can define these rules:
S -> EE -> 8E -> E + EE -> ( E )
let’s take the expression 8 + (8 + (8 + 8)) + 8:
- We start with symbol
S - Apply rule 3, it becomes
E + E - Apply rule 2 to the first
E, get8 + E - Apply rule 3 again to the second
E, get8 + E + E - Apply rule 2 to the last
E, get8 + E + 8 - Rule 4 to the only
E, get8 + ( E ) + 8 - Rule 3, get
8 + ( E + E ) + 8 - Rule 2, applied twice,
8 + (8 + (8 + 8)) + 8
the final string is made only of terminals, and it’s then valid according to this grammar.
Keeping track of what was expanded into what we can transform each expression
into a tree, called AST (Abstract Syntax Tree).
Given a grammar stored in a file a parser generator (like ANTLR) can
generate code to parse that language and build the AST.
For the majority of formal languages, like SQL or Python, there’s a
generative grammar somewhere. In Python you can even use the ast module in the
standard library to parse Python code.
Other languages like the Postgres SQL implementation make it less clear and
you have to use their internal parser
or essentially rewrite the grammar by hand since the parser is integrated in
the code of the application or is something specific for it (see SQLLite’s Lemon).
Realizing this has been baffling for me: formal languages and grammars are around since tens of years and virtually every language has some grammar, so I always assumed that there was some or a few libraries used by everyone, and likewise a mainstream grammar format. This is not really the case!
Another aspect to mention is that usually a grammar is not enough, and you need
a lexer too. This is a tool that splits a blob into “tokens”, which are the
terminals. You could have each single character as a token, but in reality it’s
usually better to split text in a smart way.
Python and YAML for example make it quite essential: indentation in Python has a semantic role, and it’s extremely complicated to write a grammar to handle the fact each line has the same indentation as the previous one or it’s a different block. The grammar can’t really “remember” the indentation when expanding a symbol. So, usually parser generators come with a lexer (that’s how compiler people call a tokenizer), and some syntactic sugar to integrate it in the grammar definition.
In addition to that, there are a plethora of algorithms to do the parsing:
LR(1), LALR, Earley, LL, etc.
The plan: write a grammar for Monicelli first
To delve into this topic (by the way, I used the word “delve” before ChatGPT, and this article is written by a human in meatspace) I decided to write a grammar for a simple language to see how the process works.
Once I have this grammar I can generate a parser for it, and try to integrate it in a web page (that is, run it on the client using JS or WASM) or a Python application. Later, I can try to implement an interpreter or a compiler for it.
I decided to go on and use Monicelli for my experiment. Monicelli is
an esoterical programming language based on the so-called “supercazzole” from the movie Amici Miei, a masterpiece of the Italian comedy
if you don’t speak Italian and don’t get the reference, just know it’s a very simple language. It supports a few variable types, functions, loops, switch-case, print, input, comments, assert and panic.
Since the language already exists I can already find a few examples of Monicelli code I can focus only on the grammar. Besides, any result may be of interest of other people curious about the language.
OK, but how can I actually create a parser??
There are plenty parser generators, and as far as I can see none is considered the “mainstream” one. As mentioned, many languages and tools implement their own thing. Not only that, there’s not even a standard format for grammars! There is the Backus-Naur form but even then there are many dialects and variations.
I looked into ANTLR, Parsimonious, Peggy, Lark, Tree-sitter and probably other five I can’t remember.
ANTLR is one of the most powerful of the bunch, and it can generate Javascript or Typescript, meaning it can be integrated in a web page and even run in a PWA offline, which I consider essential. Another advantage of ANTLR is that there is a wide collection of existing grammars useful for reference and to reuse.
Eventually however I decided to go with Tree-sitter, mainly because of the incremental update feature, the documentation and the large community.
Tree-sitter in a nutshell
Tree-sitter is a parser generator which has an interesting feature: it can react to changes to the input and update the AST incrementally. It can then be used in editors to react to changes made by the user.
It was, in fact, developed originally for the Atom text editor and has integrations for neovim, Emacs, Helix and others.
As with ANTLR, it has plenty existing grammars and can run in the browser. The Python binding is very easy to use, too (in fact every grammar is already a Python, Javascript, Swift and Go package out of the box).
Tree-sitter is particularly focused with use inside editors, and provides out of the box a mechanism to highlight syntax based on a grammar.
The joy of writing a grammar
After trying Tree-sitter and using it to write a grammar I can say I’m pleasantly surprised by how good the whole experience is, considering the task at hand is uncommon and traditionally low-level.
Installing it is as easy as npm install -g tree-sitter. The tree-sitter
command then has an init function and everything needed to test and build.
A tree-sitter grammar is essentially a grammar.js file, and optionally some
C logic to define a lexer (as is done by the Python one) to handle indentation, as mentioned.
It may sound weird that a grammar is written in javascript, but essentially the language allows to easily script out repetitive parts of the language.
A grammar rule can look like this:
non_main_function: $ => seq(
choice('blinda la supercazzola', 'blinda la supercazzora'),
optional($.variable_type),
field('function_name', $.variable_name),
optional(seq('con', $.function_arguments_def)),
'o scherziamo?',
repeat($.statement),
prec(3, $.return),
),
this is defining a symbol non_main_function as a sequence (seq) of elements,
some are literal strings (like the o scherziamo? part), others can be repeated
or named (using the field helper) or be one of a few options (the choice).
The command tree-sitter generate runs the JS code and produces the
corresponding grammar as a JSON file plus a few bindings for the lexer.
Testing the grammar
The process of writing the grammar is quite abstract, and you need to test it. Before starting I expected regression to be a big issue, and to need to write some script to test snippets against my grammar.
I was pleasantly surprised to find tree-sitter comes with a test command,
which applies the grammar to a set of given input strings and compares the AST
with the expected one.
Queries
Tree-sitter comes with a powerful query function, allowing to match patterns in an AST. This is extremely useful for linters and refactoring tools, but I did’t use it much so far.
Building the grammar and highlighting
A tree-sitter grammar is essentially a package that can be installed from the
beginning. The tree-sitter build command prepares it and it can be imported
as a Python package (for example).
Since Tree-sitter focuses on usage within an IDE, it also allows to define
syntax highlighting. An AST query can be matched with a tag (e.g. comment) to
tell an editor which style it can use on a span of text.
Also, the command tree-sitter parse can immediately produce and show an AST
for a given snippet.
Result
My grammar is here and it took a few hours to write. The errors produced by Tree sitter are quite readable, particularly when handling ambiguity and precedence.
Next steps
This was, so far, an experiment in grammars and parsing. I plan later to try and use this to write tools and hopefully a compiler to WebAssembly. I will report if and when I have interesting results.
Happy 2025!