
Add punctuation to text using Skorch
Note: The whole code for this article is freely available on GitHub
A few weeks ago I saw a talk about Skorch, a library that wraps a PyTorch neural network to use it as a Scikit-learn model.
That is amazing: I can take an existing product based on, say, a random forest, and replace only the model without refactoring anything else: the fit and predict functions have the usual interface. On the other hand, I can use the powerful tools offered by Scikit-learn, like the grid search for hyperparameters and make_pipeline to apply encoders.
It also makes trivial to compare the performance of a neural network with, say, a k-NN or a random forest, to help decide on the type of model to use based not only on accuracy but also time and resources needed to run it in a production environment.
So, I decided to try it with a toy problem, which is reconstructing the punctuation of a text. I did it in Italian because it’s my native language and I can take advantage of my own GloVe vectors and other tools, however this technique can be applied to any language provided it’s possible to tokenize it.
Problem definition
Given a function that can split a text in tokens and punctuation between them, build a model that predicts the punctuation given the tokens. Every token is followed by a sequence of characters that represent the punctuation, so multiple punctuation signs are joined.
For example, the sentence The author was an anonymous Anglo-Saxon poet, referred to by scholars as the "Beowulf poet". becomes:
('The', ' ')
('author', ' ')
[...]
('Anglo', '-')
('Saxon', ' ')
[...]
('poet', '".')
Notice how the - in Anglo-Saxon is considered part of the punctuation, because I simply used Python isalpha and isdigit to separate tokens from punctuation on a character level, but many tokeners would keep it as a single token. Also, the last token poet is followed by a single punctuation element that are actually two combined. For simplicity, I consider it as a single punctuation output class.
Given a text utterance, the problem consist in producing the sequenze of punctuation elements (that is, the second element of the tuple) given only the tokens (that is, the first element of the tuple).
Modelization and implementation
I started building a small corpus by hand, using Wikipedia articles and chat logs, but then decided to use a public one called PAISÁ, based on random web pages in Italian, mostly (68%) from Wikipedia.
Scikit-learn provides the OneHotEncoder class, which is trained on a set of strings or integers and produces one-hot vectors for them. I use collections.Counter to isolate the 40 most common characters, covering 98.2% of the total. The space character alone covers 79.9% of the cases, which means a “model” that just always return space is 79.9% correct. After that we have the comma+space (5.38%) and the period+space (2.24%). Every punctuation configuration that covers less than 0.04% of the tokens is ignored.
The OneHotEncoder is initialized with the parameter handle_unknown='ignore' to produce a vector of zeros in case the class is unknown.
For the tokens, I initially used the same approach and built 1-hot vectors of size 500 but then opted to use GloVe word embeddings to better take advantage of the semantic.
Working with these pipelines can be tricky (lots of np.reshape…), so I put every step in a single function, using assert after each declaration to verify that it does what I actually expect, for example using the one-hot encoder to decode and encode I get back the input sequence.
The function to encode tokens simply load once the GloVe embeddings in a dictionary and then replaces each token with the corresponding vector, or a 0-vector if not found. The reverse operation is not needed so no BallTree index has to be built.
For such a task an LSTM with an offset on the input vector to consider the tokens after the punctuation is probably the first approach I would try, but that cannot be directly compared with other models like a random forest since it expects a variable input size.
For this reason, I use a window of fixed length around every token to predict:

The input feature is obtained by concatenating the embedding vectors of the surrounding tokens. Unknown words are represented as vectors of 1, outside the window it uses zero vectors for padding. Every vector includes features representing the casing of the token.
when the window overflows, the padding returns 1-filled vectors (not 0-filled so the model can tell them apart from unknown words).
Now since the window size is fixed it is possible to flatten these vectors in a single one and give it to whatever model we may want. The only missing step is to define a helper function that, given an utterance, will take care of producing the \(X\) and \(Y\) matrices to pass to scikit-learn, representing a token for each line where Y contains the one-hot encoded punctuation and X the flattened window around it.
The features are then \(TOKEN\_INPUT\_SIZE * (WINDOW\_LEFT\_SIZE + WINDOW\_RIGHT\_SIZE) = 100 * (7 + 5) = 12000\), all stored as np.float32 because I found that by pyTorch maps np.float64 to torch.double and that’s the default type of One-Hot encoder output or what one gets importing a list of plain Python floats like the ones read from the GloVe embeddings. The neural network however by default expects torch.float values, so one needs to change either the network or the features. Since the embeddings are not that precise and torch.double would of course take more memory, I applied dtype=np.float32 generously to ensure everything has this type.
I tried with a 3-Nearest Neighbors, a Decision Tree and a Random Forest, that got respectively 85.75%, 77.9% and 83.8% accuracy. With all the three models I had to train with no more than 3000 utterances, which means around 76000 feature vectors (25 tokens on average for each utterance), each of size 12000. Using more data made the training too slow or impossible with my RAM: training the 3-NN with 3000 utterances took about 5 hours, with 4000 it was swapping and I had to kill it.
Creating and using a neural network in Skorch is trivial:
from torch import nn
from torch import tanh
import torch.nn.functional as F
from skorch import NeuralNetRegressor
class RegressorModule(nn.Module):
def __init__(
self,
num_units=40,
nonlin=tanh,
):
super(RegressorModule, self).__init__()
self.num_units = num_units
self.nonlin = nonlin
self.dense0 = nn.Linear(
TOKEN_INPUT_SIZE * (WINDOW_LEFT_SIZE + WINDOW_RIGHT_SIZE),
num_units)
self.nonlin = nonlin
self.dense1 = nn.Linear(num_units, 40)
self.dense2 = nn.Linear(num_units, 40)
self.output = nn.Linear(40, KNOWN_PUNCTUATIONS)
def forward(self, X, **kwargs):
X = self.nonlin(self.dense0(X))
X = self.nonlin(self.dense1(X))
X = F.relu(X)
X = self.output(X)
return X
net_regr = NeuralNetRegressor(
RegressorModule,
max_epochs=30,
lr=0.003,
)
At first a class defines a Pytorch Module with the network structure, then NeuralNetRegressor does the actual wrapping with some extra parameter used to train the network and the resulting net_regr offers the usual methods of a scikit-learn model, including partial_fit.
Notice that Skorch gets the class, not the instance, so it’s able to freely instantiate the network multiple times.
Loading and saving the parameters with pickle is simple:
# save
net_regr.save_params(f_params='punctuation_weights.pkl')
# load
net_regr.initialize() # necessary to load the weights!
net_regr.load_params(f_params='punctuation_weights.pkl')
However it has some limitations and is dangerous if the structure changes, so Skorch offers other options.
Since the network can be trained using batches and invoking partial_fit, I trained it in batches of 1000 utterances validating it every time. Notice that these are batches passed to the Skorch wrapper, not the actual batches used when training the network through backpropagation. These are by default of size 128.
This training took around 40 hours (3 days of wall clock time with many pauses to put the computer away)
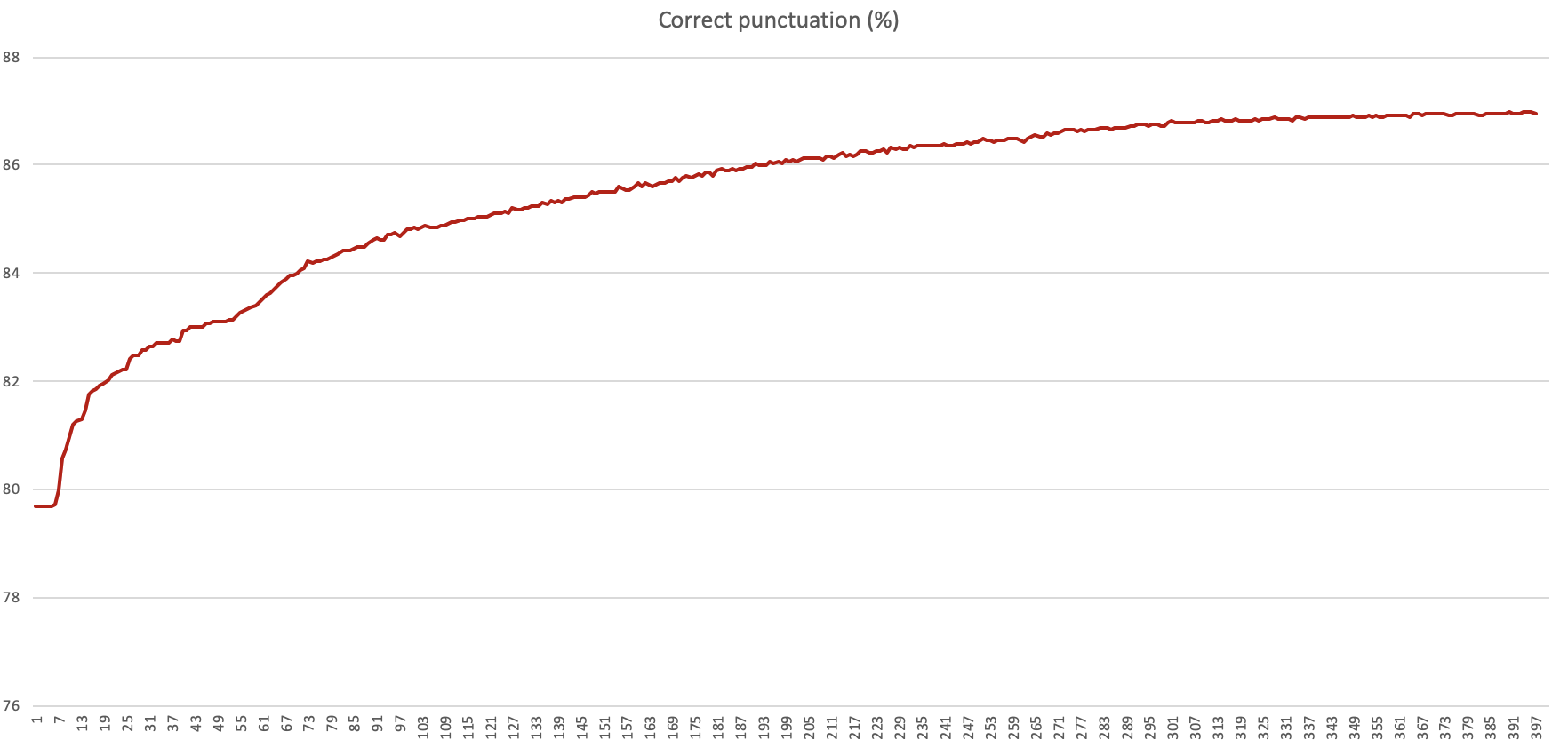
The percentage of correct prediction as training processed 400k sentences
It stops improving after reaching around 86.9% accuracy, with a training dataset of 400k utterances. The test set contained 6000 utterances (that is, around 153k tokens to be guessed) and I didn’t use any validation dataset given the size of the experiment.
It’s possible to check the results by picking some random utterances and comparing the original and the reconstructed content:
Click to expand the samples of the reconstructed punctuation
Original: Warning: mysql_connect() [function.mysql-connect]: Access denied for user ‘imc_italy’@’localhost’ > (using password: YES) in /imc/sf-active/shared/classes/db_class.inc on line 28
Reconstructed: Warning: mysql_connect() [function.mysql-connect]: Access denied for user ‘imc_italy’@’localhost’ > (using password: YES) in /imc/sf-active/shared/classes/db_class.inc on line 28
Original: Come la cometa ad annunciare una nuova era questo post apparve nella notte
Reconstructed: Come la cometa ad annunciare una nuova era questo post apparve nella notte.
Original: una volta per tutte il dominio della forza negli affari
Reconstructed: una volta per tutte il dominio della forza negli affari.
Original: Warning: mysql_fetch_array(): supplied argument is not a valid MySQL result resource in /imc/> sf-active/shared/classes/db_class.inc on line 50
Reconstructed: Warning: mysql_fetch_array(): supplied argument is not a valid MySQL result resource in /imc/> sf-active/shared/classes/db_class.inc on line 50
Original: Axel Springer (1)
Reconstructed: Axel Springer (1)
Original: DATE: Mon, 13 Oct 2003 17:49:23
Reconstructed: DATE Mon 13 Oct 2003 17 49 23
Original: né ci appartengono i chiarimenti con le virgolette.
Reconstructed: né ci appartengono i chiarimenti con le virgolette.
Original: Ci sono un sacco di lingue con un alfabeto riccamente diverso dal quello occidentale. Anzi per la verità questo riguarda la maggioranza della popolazione mondiale. Ma le tastiere che ne tengono conto non sono sempre facili da trovare.
Reconstructed: Ci sono un sacco di lingue con un alfabeto riccamente diverso dal quello occidentale. Anzi per la verità questo riguarda la maggioranza della popolazione mondiale. Ma le tastiere che ne tengono conto non sono sempre facili da trovare.
Original: La missione del Columbia rimarrà nella storia per tante ragioni, ma una è sconosciuta alla maggior parte dell’umanità. Una brutale entità proveniente dallo spazio esterno approfitta dello Space Shuttle per raggiungere il nostro mondo e usarne gli abitanti come incubatrici viventi per generare nuovi membri della propria specie, veri e propri abominii genetici, da mpiegare in una guerra senza fine. E la razza umana non ha alcun mezzo per contrastare – o anche solo comprentere – la mostruosa e cieca violenza di questa orripilante invasione dall’interno…
Reconstructed: La missione del Columbia rimarrà nella storia per tante ragioni ma una è sconosciuta alla maggior parte dell’umanità. Una brutale entità proveniente dallo spazio esterno approfitta dello Space Shuttle per raggiungere il nostro mondo e usarne gli abitanti come incubatrici viventi per generare nuovi membri della propria specie veri e propri abominii genetici da mpiegare in una guerra senza fine. E la razza umana non ha alcun mezzo per contrastare o anche solo comprentere la mostruosa e cieca violenza di questa orripilante invasione dall’interno.
The network clearly learned to put the period at the end of sentences and before capitalized words, and did an excellent result in learning the punctuation in the error message that presumably appears multiple times in the dataset, but rarely adds commas, quotes or other elements. It also learned where to put the apostrophe.
Learnings
I hoped for the network to learn how to insert commas, but the model never use them. Probably the window is too small for the model to capture the structure of the sentence, but increasing it would in turn make the features vector longer and make it harder to use models like the k-NN.
When training the network initially I used a high number of epochs and a relatively low learning rate, and kept it even after switching to partial_fit. I assumed that partial fit would have ignored the parameter and trained for a single epoch but it’s indeed running many epochs on every single batch of samples. I kept the model running nonetheless, eventually taking a long time to train. Additionally, I didn’t store the model during the training (assuming it would be fast), but would have been better to use from the beginning the functionality to store the weights every time the validation loss goes down in a given folder.
Next steps
The goal of this experiment was to try the library, I have no real usage for this specific model except curiosity. A possible next step could be to expand the features with PoS tagging (it remains the problem of needing a PoS tagger that doesn’t use the punctuation as an input feature), drop the compatibility with other models requiring a feature vector of a fixed size and go with an LSTM to better model a long sentence.
This experiment didn’t include any hyperparameter optimization, but Skorch allows integrating with Scikit-learn GridSearchCV and it could be worth spending time trying different network structures and activation functions.
Another missing element is the character-level modelization of the tokens: the GloVe vectors file is quite comprehensive, but in case of proper nouns, emojis or neologisms the placeholder vector looses information.