
Fleximatcher, a library to help parse natural language
Note: this is an old article and while the software is still available and I think the idea is pretty you probably want to give a look to this. The software here described is probably more flexible, but harder to use.
Some months ago, I stumbled across this amazing article about transforming an arbitrary English text in a patent application. The underlying pattern library allows, among other nice things, to find patterns like “The [an adjective] [a noun] and the [a noun]” easily, look for hypernyms (“is a” relationships between expressed concepts, for example “animal” is an hypernym of “cat”) in WordNet, and conjugate verbs in various languages comprehending Italian.
With a library like this extracting information from text becomes a lot easier, but unfortunately there are no exact replacements for this in Java, and the coverage of Italian is partial (no hyperonymy information, a small set of PoS tags), so why not try to create a specific library in Java?
Reinventing the wheel: UIMA and GATE
At first the idea was to integrate a PoS tagger like the one from OpenNLP and match expressions like “The [pos:ADJ] [pos:SS] and the [pos:SS]“, or “[hyp:animal]” allowing the user to easily express patterns and look for them, then I started thinking about additional patterns like “[r:[a-z]+[0-9]]” to match regular expressions, or “[reddit_nick]” to match Reddit usernames, and found that providing a set of core expressions and letting the users define their own could be way more useful.
Moreover, an user may want to define expressions to match common patterns, for example “[r:[1-9][0-9]] [r:[AP]M]*” may be assigned to the tag “hour” in order to directly write expressions like “it’s [tag:hour]” to match “it’s 3 PM“, so user-defined expressions may recursively match patterns with other expressions. This is exactly what generative grammars do, and while we are at it why not let the user defined expression add metadata to the matched text and read metadata added by other rules?
If this does ring a bell, it’s because the idea isn’t new: annotation engines like UIMA and GATE do exactly this.
The problem is that those are both pretty hard to use and configure, though uimaFIT is somehow making things easier, and I wanted a library that could be used immediately and embedded in an application without writing XML configuration files, installing Eclipse plugins or use standalone extra applications to test the results.
So, a Java 8 library called Fleximatcher was born. The name stands for flexible matcher (my boss says I’ve plenty of fantasy 🙂 ) The usage is pretty simple:
- Add expressions (the pos or hyp in the examples above) and bind them to your annotators, or use built in annotators.
- Add tags, that are expressions matching patterns (the hour tag above).
- Ask the library whether a string matches a pattern, and if so which part of the string match which expressions, and which annotations are returned.
JSON is adopted as a format to express annotations, and to define tags, which in the end are rules of a generative grammar, is possible to load a TSV file in this format:
adjective_attribution [it-pos:Ss] [it-pos:As] {‘name’:#0#,’attribute’:#2#}
information [tag:adjective_attribution] {‘name’:#0.name#,’attribute’:#0.attribute#}
The first rule matches Italian singular names (Ss) followed by Italian singular adjectives (As), and create a JSON string with the keys name and attribute and the name and adjective as values, since #0# is the first matched expression, #1# is the space between them and #2# is the annotation.
The second rule takes what was marked by the first and encapsulate it in another JSON string, taking the attributes from it.
This way is possible, with a single line of a TSV file, to define rules that generate annotations based on annotations from other rules, reading both the annotated text spans and the annotation attributes. It’s also possible to define more complex tags with a custom tag class.
Using about 70 rules it was possible to extract hyponyms, adjective attributions to names and subjects and objects of verb from a whole dump of Wikipedia, a topic I’ll talk about another time.
Parsing with no leftmost derivation
The parser is a top-down one, it tries to match the expressions composing the given pattern and expand tags by matching the correspondent patterns. Since expressions like PoS tags are identified by looking at the surrounding text, and ambiguous grammars are fine (multiple interpretations can be returned), leftmost derivation used by LL parsers is difficult to get.
To be faster the parser uses a trick (two if we consider caching): since annotators can only add annotations, never remove or modify existing ones, if an annotator is called twice on the same text and with the same number of annotations, we can safely assume that the second time it will not retrieve anything, and avoid trying.
This is done by analyzing the chain of annotation handlers. Annotation handlers are for Fleximatcher what the CAS is for UIMA: an element which stores annotations from different annotators. Fleximatcher annotation handlers are of course a lot simpler, they just allows annotators to store and retrieve annotations which are kept in memory, but offer the possibility of searching for sequences of adjacent annotations and get sub-handlers which are wrappers passed around when expanding an expression to its own pattern.
Each time a tag is asked to annotate a text, it checks whether it was called previously querying the annotators up to the hierarchy and the amount of annotations. If it finds another one with the same number and the same tag expression, it means that due to the deterministic nature of annotators it won’t add annotations and the recursion stops.
This is done not just for efficiency, but also to let the user detect cycles and anomalies int he given grammar: if we can exclude “fake” cycles there’s less noise hiding real ones, which throw specific exceptions when found.
To make the parsing easier, a PoS tagger for Italian, based on OpenNLP and with tens of different words, is already present, and a web application allows to define tags and test patterns on text on the fly, seeing the results in a webpage
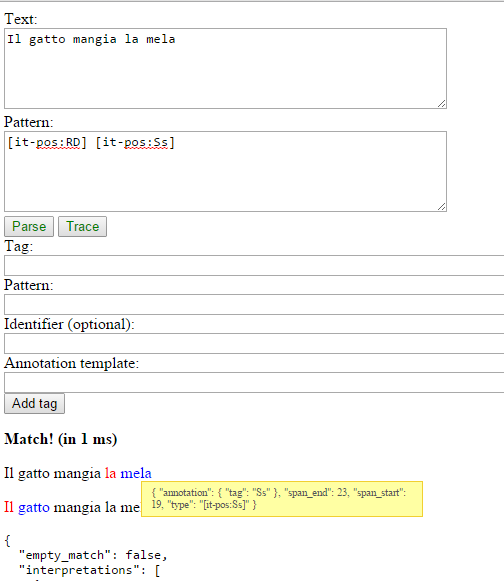
Fleximatcher web interface, showing the annotations over a snippet of text
The application is just a REST interface to Fleximatcher, and allows to call the library from other languages.
It would be nice to adapt the library to Apache Stanbol enhancement engine, while for UIMA the project Ruta seems a better fit.