
Making a fully static map, part 3: Text search
NOTE: a complete interactive demo of the final result is here.
In the previous post of this series, we saw how to generate vector tiles starting from an OpenStreetMap PBF extract using Tilemaker.
After the article I refined the process and wrote a Python tool to automate it, adding the possibility to index named objects like streets and shops.
Usually, such a search would be performed using a geocoding service that can handle the full text search with all the nuances like alternative spellings, typos and ambiguities.
However, for small areas or limited user cases it’s enough to perform a string search, looking for an exact match and showing the findings to the user
Extracting the location names
The first step in our process is to extract all the names that the user may want to search, and associate them with coordinates on the map. This includes streets, shops, schools, monuments and many other geographical features.
In OSM terms, a name is a tag (the tag name, in fact) associated with a node, way or relation. The convention is that the name tag refers to the most common name for a feature, in the local language, which as you can imagine can be tricky in multi-lingual areas. Additionally, names in different languages can be provided, for example using the tag name:ja you can get the Japanese name (エッフェル塔), if defined. Important landmarks like the Tour Eiffel are often translated in many languages.
This data is all included in the PBF export from OSM and the regional extracts. These files are in a binary format defined by OSM which encapsulates protobuf data but is not protobuf itself, meaning you cannot just use protoc to generate a parser. Luckily, there are libraries to process this format.
I used Pyosmium, a Python binding over libosmium that lets us parse a pbf file directly in Python, processing it as a stream of elements. It’s very fast and by using stream processing you can handle large files.
The library generates a synthetic area object to represent closed ways and relations, which is extremely useful when working with areas that have “holes” because they can be handled automatically, saving a lot of time.
Another useful feature from pyosmium is the direct creation of shapely objects correspnding to the features, making the coordinate extraction a breeze.
The command soi_list_named_locations in the tool can process a PBF file and extract all the named locations, allowing to specify different tags to extract/ For example --tags 'name,name:it,name:en' will extract the local name and the Italian and English ones when available. When they are the same for the same features, only one is retrieved.
The result is a JSONL file where each line has this format:
{"name": "Capo Ferrato", "lat": 39.2427799, "lon": 9.5694392}
notice that the name key here is always called “name” regardless of the tag that was extracted.
To give you an idea of what to expect, the PBF extract for Italy includes 3.2 million rows.
Now that we have the names, we need to arrange them in a format that is palatable to a static frontend. That is, we need to generate an index.
Full text indexing in the frontend
Geocoding for small, simple use cases can be approximated as a full text search problem. It’s not, in particular when we care about addresses, but is fine if we have only one city or a small region without much ambiguity.
When you have a backend, full text search can be done using tools like Elasticsearch or the PostgreSQL functions.
Without a backend, I found two options:
- Lunr.js is extremely popular for static websites, and can be customized for this use case, but assumes the whole index can be loaded as a single JSON
- Pagefind is a new tool that can index HTML pages into many files arranged by tokens. These files constitute a TF-IDF index that can be fetched on demand by the client, allowing numerous documents to be scanned. It’s an interesting option for static websites, and since it directly processes the HTML it’s agnostic to the tool (Jekyll, Hugo, etc.).
Pagefind is closer to what we need, but is designed to index HTML documents, not short strings. As a workaround I tried to create many small HTML files containing only the named entities (addresses, shop names, etc.) but the tool required more than 30 GB of RAM to process around 30k documents, corresponding to a small city. I didn’t find ways to process the data in chunks using the disk, or avoiding the workaround of creating fake HTML documents; overall, I’m abusing the tool to do something really outside the scope, so I ended up implementing something similar from scratch.
A simple static index
My approach for this has been to split the data into files representing prefixes.
The process is as follows:
- Retrieve a name from the name file, e.g.
Viale Fulvio Testi 130 - Make it lowercase:
viale fulvio testi 130 - Split it into words using a regex,
[^\w]+(it splits on all Unicode non-word characters):['viale', 'fulvio', 'testi'] - Store the original JSON in files corresponding to the first 3 characters of each token, in this case
via.json,ful.jsonandtes.json
the frontend will do the same operation on the input query, and retrieve the JSON file corresponding to the prefix, so as soon as the user types “fulvio” the file ful.json will be retrieved and filtered for matches. The user does not need to write the entire word, or place the tokens in the same order.
Some assumptions are made here:
-
Using 3 characters the resulting files will be small enough that we can load them when needed. For the whole Italy the largest file is
san.jsonand it’s 18MB (less than 4 MB when compressed, using flatbuffers can reasonably be reduced even more), large but acceptable. -
The lowercase and regex split functions produce the same result in the Python indexer and in the JS consumer. This is true as long as the locale is the same, and the regex is based on Unicode classes that are standardized.
-
No complete place name is shorter than 3 characters. A name like “santa fe” is fine because we need one token to be at least 3 character in order to retrieve the associated file.
Additionally, the script has a flag to specify stopwords to ignore, for example to index Italy I ignored the word via (street) to improve the performance.
If you know some NLP you are probably wondering how this applies to different languages, and I did in fact run experiments on a few datasets on different countries including CJK locales and ask a Japanese colleague to try the result.
For a language using ideograms like Chinese or Japanese, the prefix length can be set to 1, so for example when the user searches for 秋葉原 (Akihabara, a famous area of Tokyo) the file 秋.json will be fetched. This is possible as long as the dataset is mostly based on ideograms, Japanese also uses two syllabic writing systems but turns out the usage is rare enough (and there are enough possible syllables) that the index can be used with a single Unicode codepoint prefix. The frontend component is written in Typescript and is quite simple. The index has a metadata file containing the prefix length and the stopwords, because these details must be known to the client to correctly access the index.
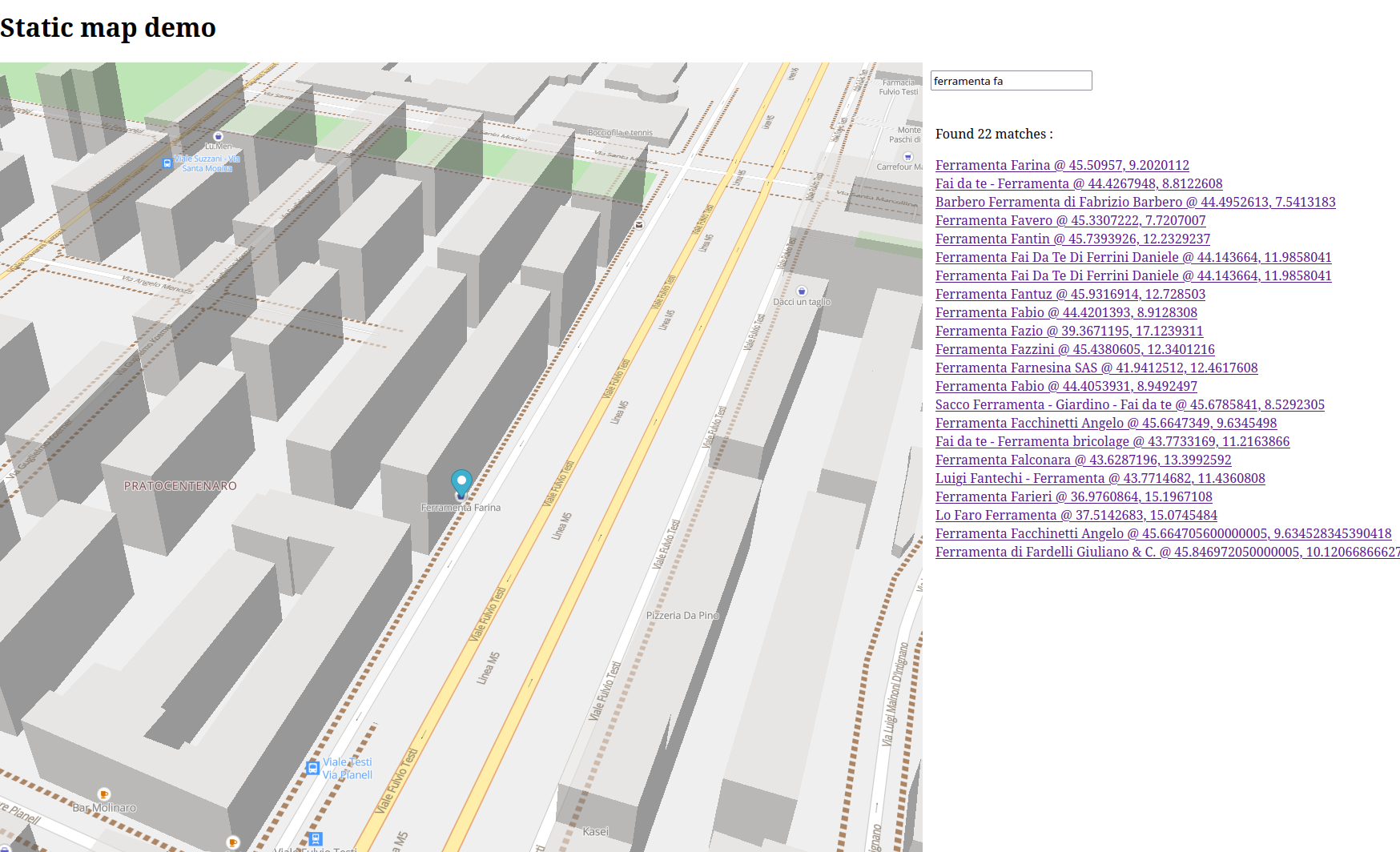
An example of the search being performed, notice that the query is not complete
Tokenizing
Tokenizing is done with a simple regex. Normally when dealing with multiple languages a proper tokenizer is needed, in particular when dealing with languages like Thai or Chinese that do not use spaces.
The problem is that there aren’t many options to perform tokenization in the browser. Chrome and Safari do have the Intl.Segmenter class for this, but sadly Firefox does not implement it yet. For the moment, a regex must suffice.
Navigation (Not currently possible)
Once the user can search for points on the map, it could be useful to add some option for navigation. Knowing the shortest or fastest path in the road network could be useful, for example, to estimate the walking distance between two locations.
Again using Pyosmium, I created a script, soi_extract_road_network, that can store in a SQLLite database the network of roads for cars, bikes and pedestrian. This is a graph with nodes and edges, every node is a proper OSM node with its identifier and coordinates, while edges refer to the possibility of moving from one node to another using a specific mode of transportation. The graph is directional to account for one-way routes.
When processing ways, I assume that every way that intersect another had a node in common, which is the proper way to map them and is mostly the case. Sometimes it’s not, and one should spot intersections and use the level tag to infer if two ways are connected or not (e.g. bridges or tunnels).
The issue with this data is that it’s large. When processing the PBF file for Italy I got:
54,840,951nodes110,138,095walk edges106,640,270bicycle edges105,390,544car edges
when each node id requires 4 bytes that’s 1.6 GB to represent the walking edges.
Many nodes are very close, for example when there’s a curve the graph will contain tens of nearby nodes. I added a --collapse-distance flag to aggregate nearby nodes preserving the topology, it helps but even when used aggressively the graph size remains just too large to be processed.
A possibility would be to produce small files for small areas like cities or towns, but one needs some logic to chunk the surface in meaningful blocks and let the frontend find out which one to load. Once done it’s easy to use a library like Graphology to perform the shortest path search.
I created a separate demo based on PgOSM-Flex data that performs bike routing decently for the city of Berlin, Germany. The approach used in the demo is to load the data into PostGIS and process the graph there, exporting a JSON that the browser can load and use on the fly. For a medium-sized city such a file is quite large, but can be loaded with a reasonable delay (less than 10 seconds usually). The demo also shows how to perform the same operation in Python using networkx.